
Article: Full PDF and Image Support in Dedoose 7 Release
Tags
- All
- Training (4)
- Account Management and Security (9)
- Features of Dedoose (9)
- Dedoose Desktop App (1)
- Dedoose Upgrades and Updates (5)
- Dedoose News (6)
- Qualitative Methods and Data (11)
- Other (5)
- Media (5)
- Filtering (5)
- Descriptors (10)
- Analysis (22)
- Data Preparation and Management (20)
- Quantitative Methods and Data (5)
- Mixed Methods (20)
- Inter Rater Reliability (3)
- Codes (26)
- Tags:
- Media

Dedoose 7 is here and we are thrilled to introduce some GREAT new features and other HUGE improvements. First up, NATIVE IMAGE AND PDF excerpting and coding. Let’s take a look… In the past, Dedoose had some OCR technology that would work to convert PDFs to inline documents for excerpting and tagging. Given OCR limitations, this approach brought with it some less than desirable issues. Tables or images in a PDF would be brought in as images, but the content of the image could not be excerpted or tagged. Further, the loss of formatting was also problematic for some files.
Now, however, Dedoose 7 is here and it’s a real game changer. After a tremendous amount of work, our awesome Tech Team has now added image based PDF support and image importing, excerpting, and coding capabilities. To bring you the best of both worlds, you now have the option to importing PDFs as native image-based media or make use of the OCR technology to import the file as a document-based media. Enough chat; let’s get to importing some PDFs as images!
- Click Import Data
- Click Import PDF
- Click Submit
- Locate your PDF file (or files) on your local computer and click Open to upload
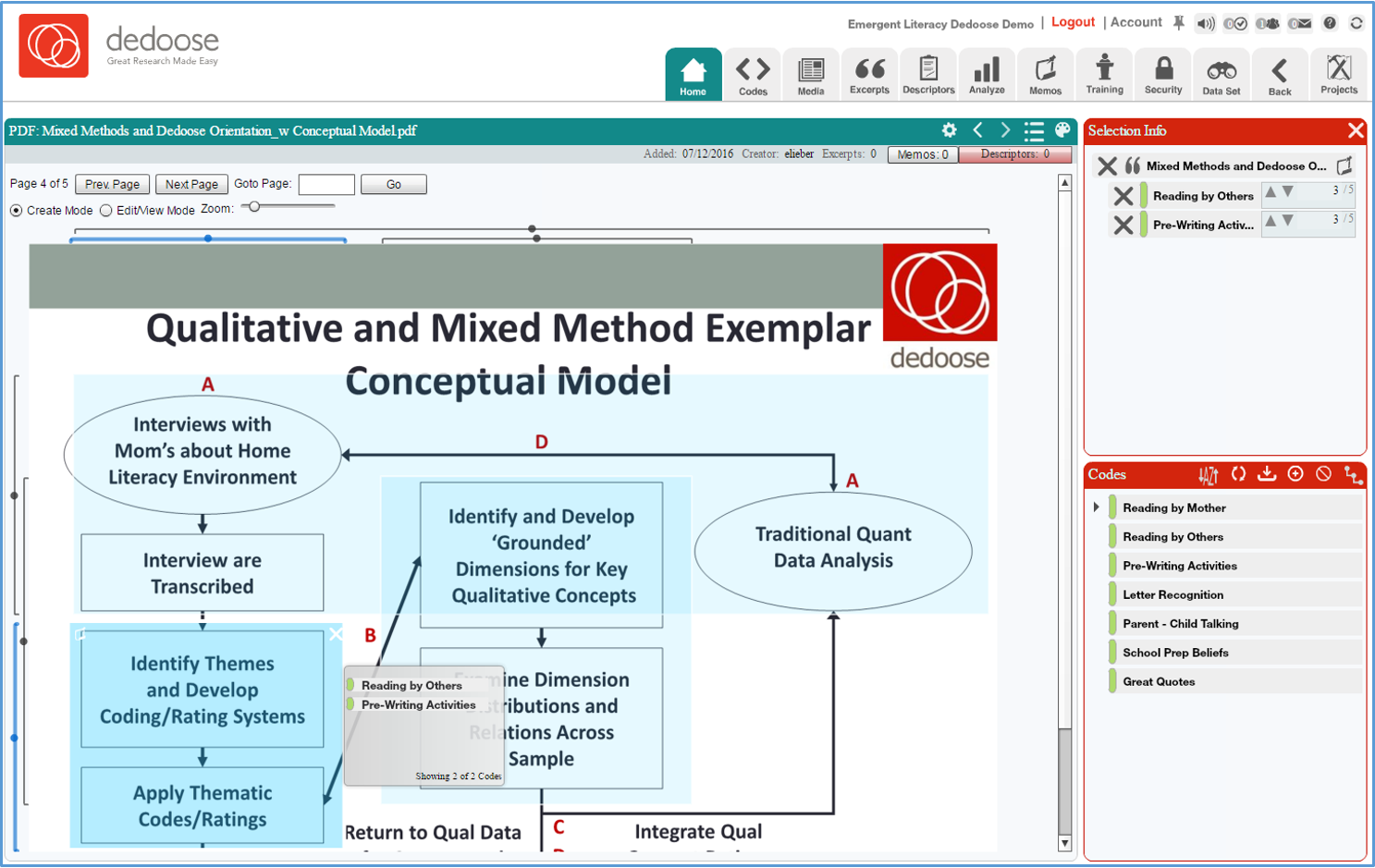
- Open a PDF file you wish to excerpt just like accessing other media in Dedoose
- Grab a region of the PDF that you wish to code by defining a rectangular section and you’ve create a image excerpt…and note that the excerpted region can be moved or resized
- Double click or drag and drop codes to apply them just like with any excerpting
- Finally, you can zoom in or out and move through the PDF page by page or by jumping to a particular page.Screenshot of Dedoose PDF Functionality
For more information on Image based PDFs, check out our Help Center page on PDF coding at:
What can I do with an image based PDF file?
Image Coding
Previous to Dedoose 7, you could only paste images into documents to import to Dedoose, so you could see them but not excerpt the image itself. Well, now the sky’s the limit. After a tremendous amount of work, our awesome Tech Team has now added native image importing, excerpting, and coding. Let’s take a walk through importing and coding an image:
- Click Import Data
- Click Import Images
- Select the images you want to import….jpg, png, bmp, or gif formats will work
- Click Open
- Dedoose will automatically open the image you just uploaded or let you know they are all imported if you imported more than one

Now that your images are in, let’s get to coding!
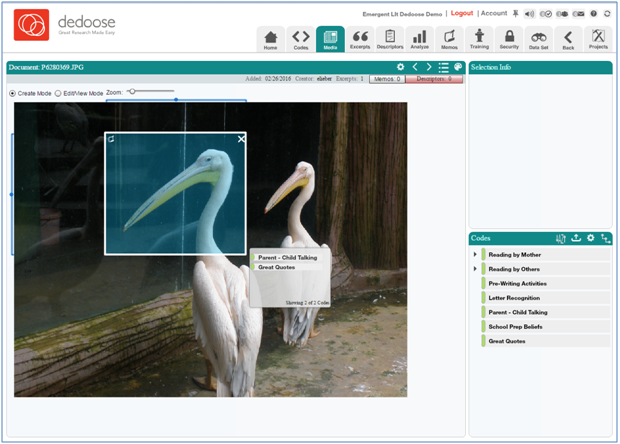
- If not already in view, open a PDF file you wish to excerpt just like accessing other media in Dedoose
- Grab a region of the image that you wish to code by defining a rectangular section and you’ve create a image excerpt…and note that the excerpted region can be moved or resized
- Double click or drag and drop codes to apply them just like with any excerpting
- Finally, you can zoom in or out on the image using the zoom controls
For more information on image coding, check out our Help Center article on Image Coding at:
What can I do with an image file?
AND MORE
Beyond the wonderful new PDF and image handling, we’ve made some major upgrades to Dedoose’s Application Server Infrastructure to increase throughput i.e. it can do more at once… a LOT MORE. What does this mean for you? Much snappier response times, fewer if any application hangs, far fewer of the ‘errors’ that can pop up, and overall Dedoose to handle much more user demand than ever before.